View Independent Generative Adversarial Network for Novel View Synthesis
Abstract
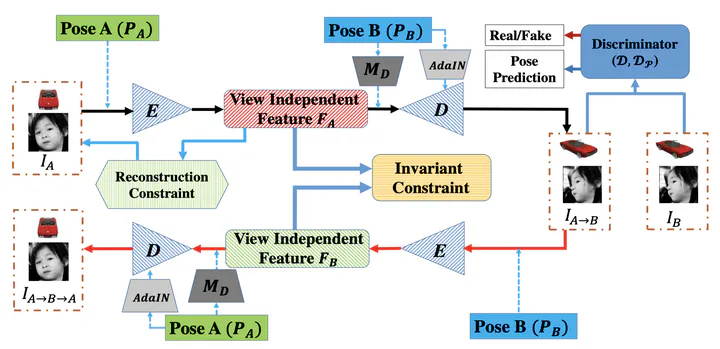
Synthesizing novel views from a 2D image requires to infer 3D structure and project it back to 2D from a new viewpoint. In this paper, we propose an encoder-decoder based generative adversarial network VI-GAN to tackle this problem. Our method is to let the network, after seeing many images of objects belonging to the same category in different views, obtain essential knowledge of intrinsic properties of the objects. To this end, an encoder is designed to extract view-independent feature that characterizes intrinsic properties of the input image, which includes 3D structure, color, texture etc. We also make the decoder hallucinate the image of a novel view based on the extracted feature and an arbitrary user-specific camera pose. Extensive experiments demonstrate that our model can synthesize high-quality images in different views with continuous camera poses, and is general for various applications.
Type
Publication
Proceedings of the IEEE International Conference on Computer Vision (Oral, Acceptance Rate: 2.1%)